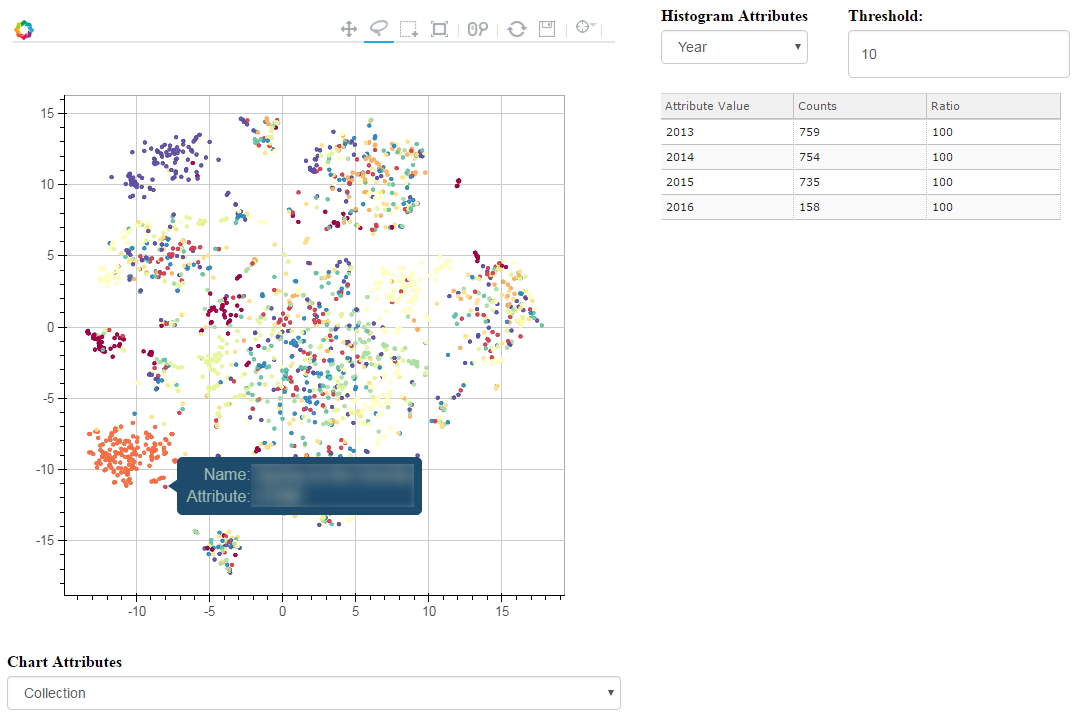
 T-SNE, PCA and other dimensionality reduction algorithms have always been a good way to visualize high-dimensionality datasets. Unfortunately, most of the time, the visualization stops there. If another view of the data is needed, a new chart needs to be computed, projected and displayed.
T-SNE, PCA and other dimensionality reduction algorithms have always been a good way to visualize high-dimensionality datasets. Unfortunately, most of the time, the visualization stops there. If another view of the data is needed, a new chart needs to be computed, projected and displayed.
Toolkits like Bokeh have been a great help to build interactive charts, but the analysis dimension has always been a bit neglected. Last week-end, I took a few hours to glue some Bokeh components together and built an interactive visualization explorer: Chart Miner.
Continue reading “Chart Miner – Exploring 2d Projections”
Category: Visualization
15 Years of News – Analyzing CNN Transcripts: Visualizing Topics
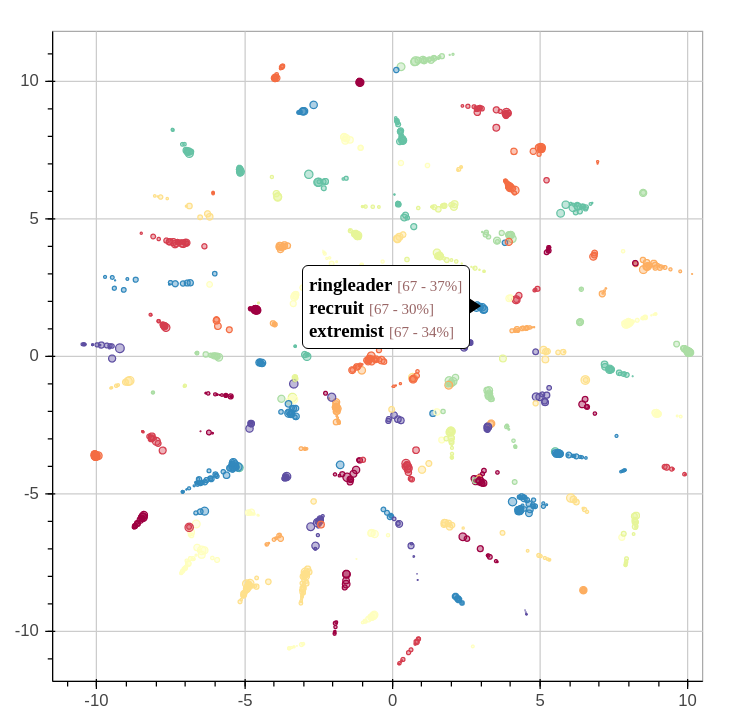
By extracting several topics from our news corpus, we gained a 10,000 feet view of corpus. We were able to outline many trends and events, but it took a bit of digging. This article will illustrate how the topics relate each to one another. We’ll even throw a bit of animation to take a look back the last 15 years.
When we extracted the topics from the corpus, we also found another way to describe all the news snippets and words. Instead of seeing a document as a collection of words, we could see it as a mixture of topics. We could also do the same thing with topics: every topics is a mixture of words used in its associated fragments.
Continue reading “15 Years of News – Analyzing CNN Transcripts: Visualizing Topics”
15 Years of News – Analyzing CNN Transcripts: Topics
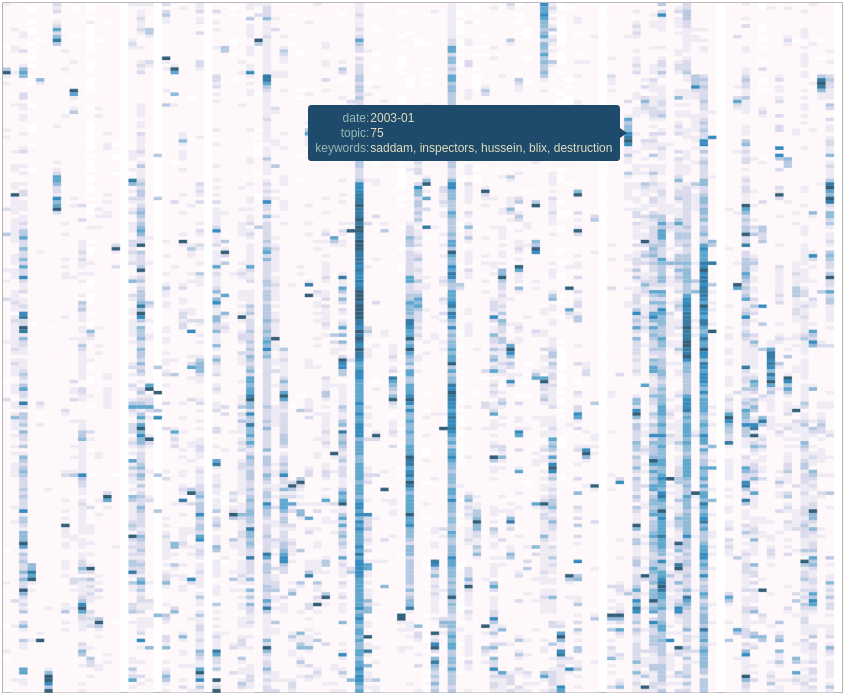
As we saw in the previous article, temporal analysis of individual keywords can be very interesting and uncover interesting trends, but it can be difficult to get an overview of a whole corpus. There’s just too much data.
One solution would be to group similar subjects together. This way, we could scale down a corpus of 500,000 keywords to a handful of topics. Of course, we’ll be losing some definition, but we’ll be gaining a 10,000 feet view of the corpus. In all cases, we can always refer to the individual keywords if we want to take a closer look. Continue reading “15 Years of News – Analyzing CNN Transcripts: Topics”
15 Years of News – Analyzing CNN Transcripts: Timelines
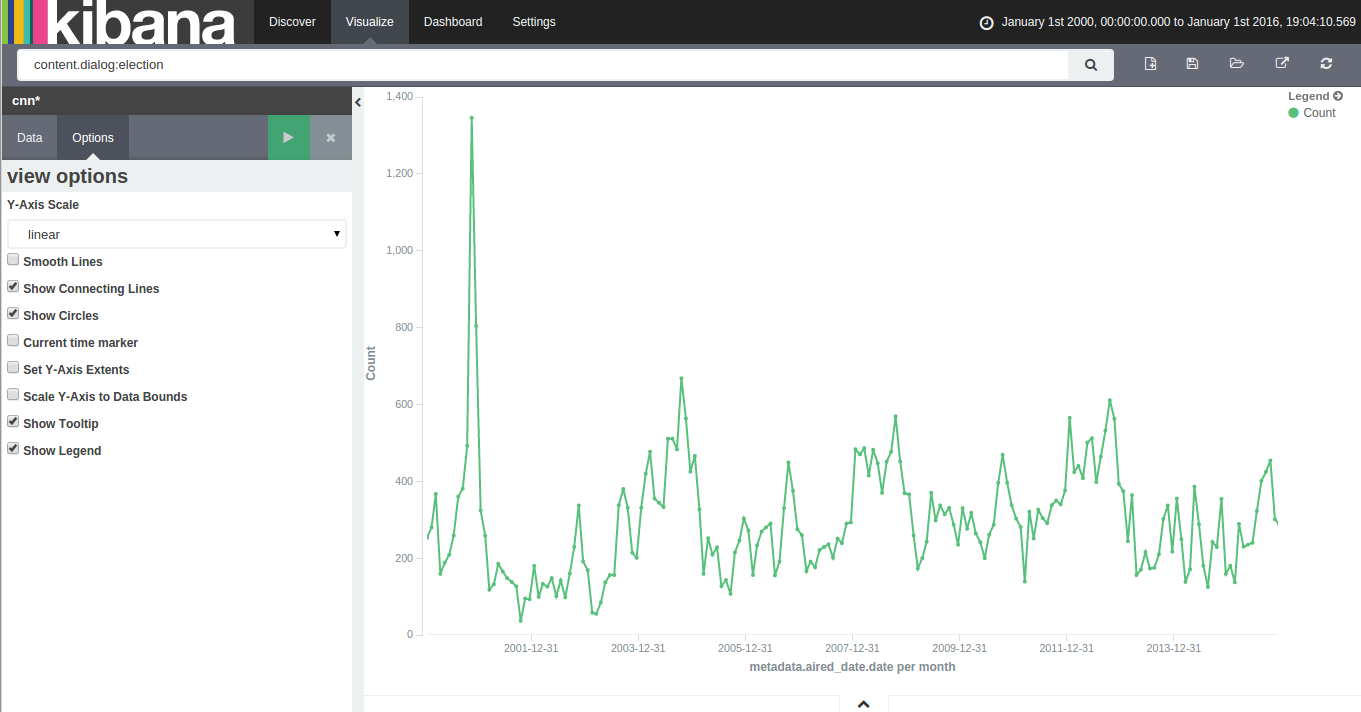
With 15 years of CNN transcripts loaded a database, I could now run queries to visualize the occurrences of words – like names – across time. Since I used a textual database name ElasticSearch, I could use Kibana to chart the keywords. Kibana is a good tool to build dashboards, but it’s not really suited to analyze extensively time series because it lacks an easy way to add several search terms on the same chart. Also, it doesn’t easily show percentages of occurrences in a corpus for a giving time period instead of absolute occurrences. This makes Kibana a good tool for a quick look at the data or to debug an issue with our transcript scrapper.
With this in mind, I used Amazon’s DynamoDB database, the HighChart Javascript library and a bit of glue logic to build my own tool to visualize the last 15 years of News!
Continue reading “15 Years of News – Analyzing CNN Transcripts: Timelines”
Map of scientific collaboration (Redux!)
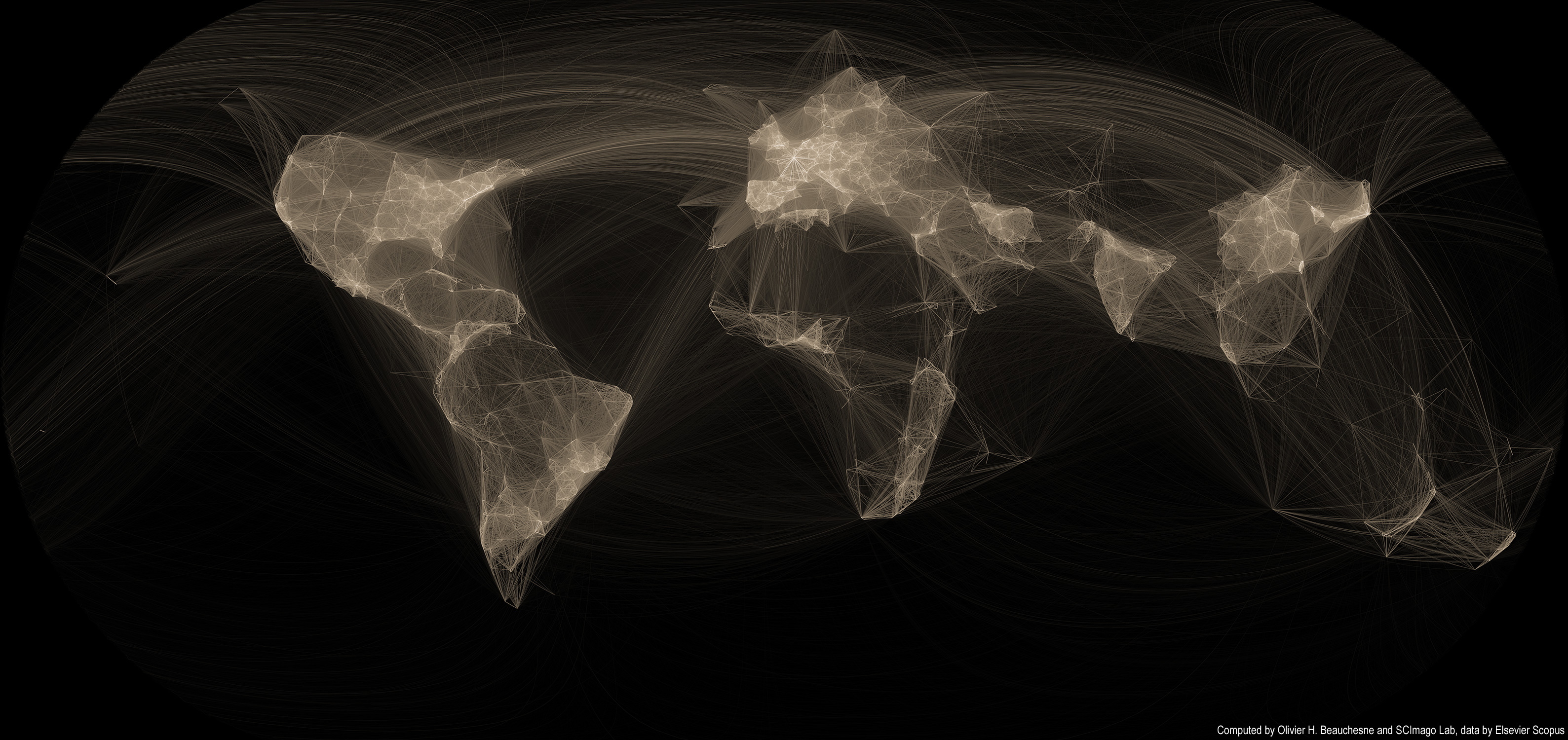 Several years ago, I created a map of scientific collaborations. The attention this map obtained surpassed my wildest expectations; it got published in the scientific and popular press all around the world! I had mainly forgotten about it until I received an email that rekindled my interest in this visualization and I thought it was high time to revisit this visualization.
Several years ago, I created a map of scientific collaborations. The attention this map obtained surpassed my wildest expectations; it got published in the scientific and popular press all around the world! I had mainly forgotten about it until I received an email that rekindled my interest in this visualization and I thought it was high time to revisit this visualization.
Unfortunately, scientific papers (and associated data) are closely guarded and only a handful of firms have full access to them. I now work in a very different field, so I lost access to this dataset. But while perusing my Twitter feed, I came across the very active feed of Scimago Lab. Their social media presence and their incredible interactive visualizations convinced me that they might be interested in collaborating. I sent off an email to their founder, Félix de Moya and, lo and behold, he was interested in collaborating. Cool!
Read on for more maps and an overview of the methodology >>
Continue reading “Map of scientific collaboration (Redux!)”
Thèmes abordés sur Twitter durant l’élection provinciale de 2012
 Suite à la visualisation des tweets publiés durant la grève étudiante, le professeur Frédérick Bastien de l’Université de Montréal m’a approché afin de participer à l’ouvrage Les Québécois aux urnes.
Suite à la visualisation des tweets publiés durant la grève étudiante, le professeur Frédérick Bastien de l’Université de Montréal m’a approché afin de participer à l’ouvrage Les Québécois aux urnes.
J’ai donc rédigé un chapitre traitant des thèmes abordés sur les médias sociaux. L’élément central du chapitre était une visualisation de tous les tweets publiés durant la campagne électorale.
Continue reading “Thèmes abordés sur Twitter durant l’élection provinciale de 2012”
Distribution du financement politique à Montréal
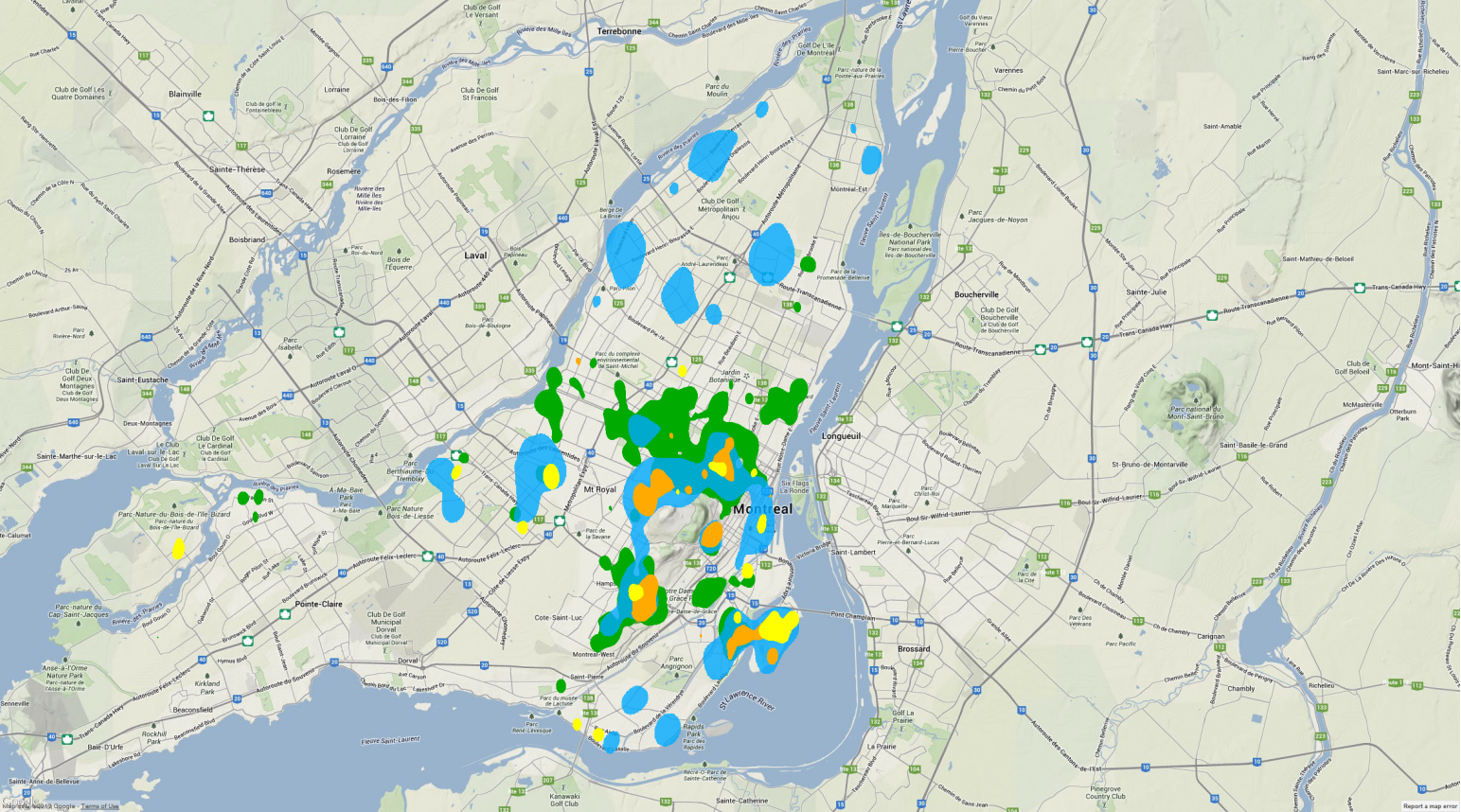
Comme lors des années précédentes, La Presse a conçu une carte du financement politique à Montréal. Les responsables de ces cartes (Cédric Sam, Pierre-André Normandin et Thomas de Lorimier) ont dû composer avec l’absence de données gouvernementales standardisées et contacter chaque parti politique pour obtenir ces données.
Le résultat est très intéressant et ils font preuve d’une très grande générosité en partageant les données recueillies. Les données ouvertes comprennent la latitude et la longitude de chaque don ce qui facilite leur utilisation dans les logiciels GIS comme ArcGIS et Quantum GIS. Je me suis donc amusé ce dimanche à analyser et créer des cartes illustrant la distribution des dons. La carte à gauche illustre les concentrations de financement pour chaque parti. Par exemple, il y a une concentration de financement pour Projet Montréal sur le Plateau, Villeray et Hochelaga.
Cliquez sur le lien à droite pour lire (et voir!) la suite >>
Continue reading “Distribution du financement politique à Montréal”
A Map of the Geographical Structure of Wikipedia Links
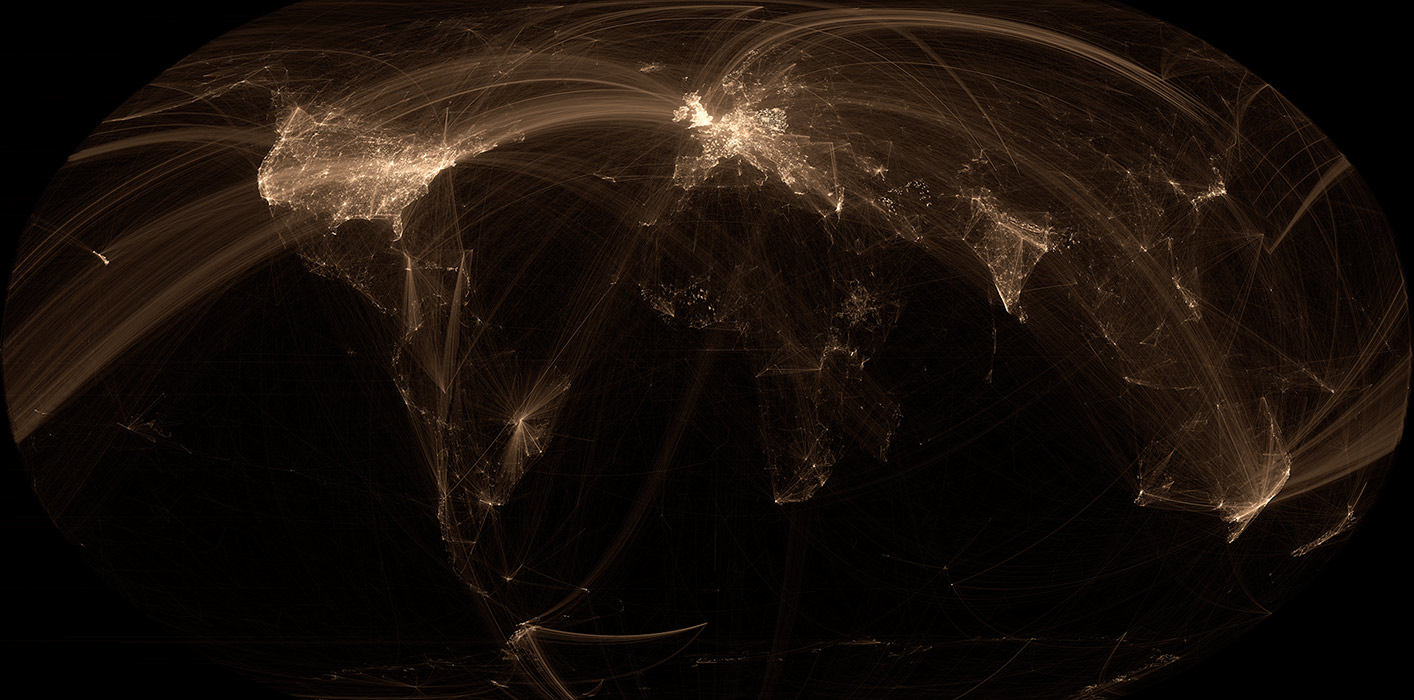
There are a lot of Wikipedia visualizations. Some concentrate on article contents, others on the links between articles and some use the geocoded content (like in my previous blog post).
This new visualization is novel because it uses the geographical content of Wikipedia in conjunction with the links between articles. In other words, if a geocoded article (that is, an article associated with a location like a city) links to another geocoded article, a line will be drawn between these two points. The result can be found on the map on the left.
Read on for zoomed views, slideshows, browsable maps, etc.
Continue reading “A Map of the Geographical Structure of Wikipedia Links”
A Map of the Geographic Structure of Wikipedia Topics
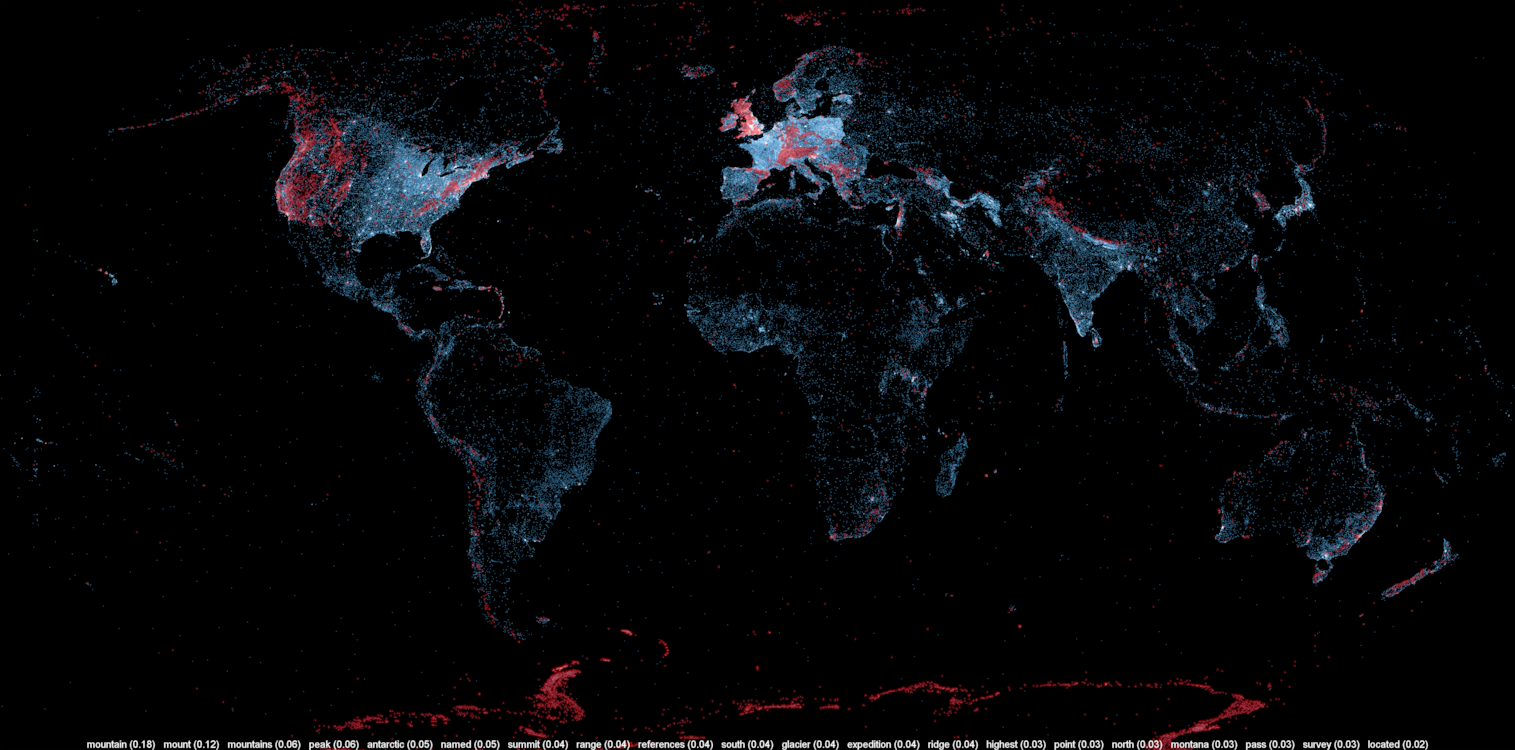
A large number of Wikipedia articles are geocoded. This means that when an article pertains to a location, its latitude and longitude are linked to the article. As you can imagine, this can be useful to generate insightful and eye-catching infographics. A while ago, a team at Oxford built this magnificent tool to illustrate the language boundaries in Wikipedia articles. This led me to wonder if it would be possible to extract the different topics in Wikipedia.
This is exactly what I managed to do in the past few days. I downloaded all of Wikipedia, extracted 300 different topics using a powerful clustering algorithm, projected all the geocoded articles on a map and highlighted the different clusters (or topics) in red. The results were much more interesting than I thought. For example, the map on the left shows all the articles related to mountains, peaks, summits, etc. in red on a blue base map. The highlighted articles from this topic match the main mountain ranges exactly.
Read on for more details, pretty pictures and slideshows.
Continue reading “A Map of the Geographic Structure of Wikipedia Topics”
Traquer les avions en temps réel avec une antenne et 20$
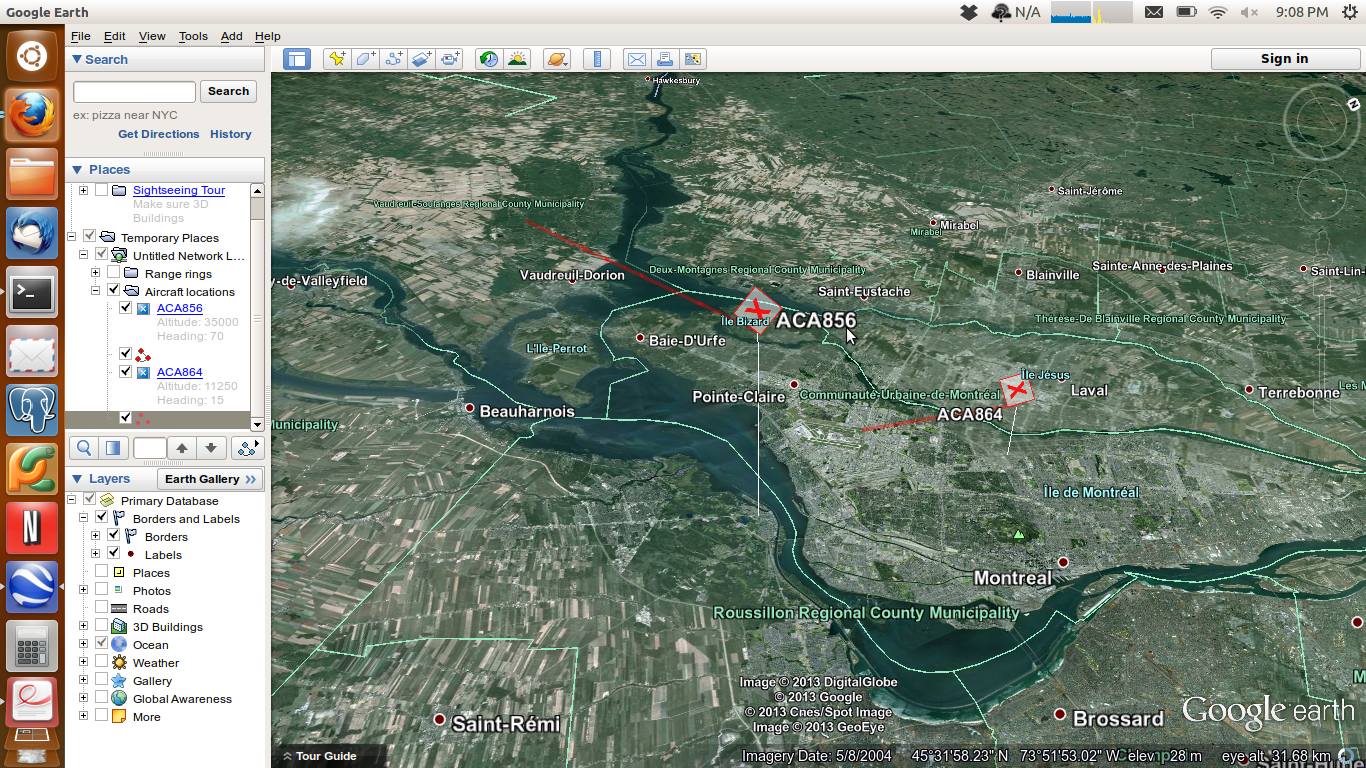 Un super-bidouilleur a récemment découvert qu’en utilisant une certaine marque (RTL) de clés USB pour écouter la télé, il était possible de capter et décoder une très grande partie du spectre radio à l’aide d’un petit logiciel (RTL-SDR). Plusieurs appareils, comme le USRP, permettaient déjà de le faire depuis quelques années, mais ces appareils étaient plutôt dispendieux et exigeaient des connaissances plutôt poussées en électronique et en informatique.
Un super-bidouilleur a récemment découvert qu’en utilisant une certaine marque (RTL) de clés USB pour écouter la télé, il était possible de capter et décoder une très grande partie du spectre radio à l’aide d’un petit logiciel (RTL-SDR). Plusieurs appareils, comme le USRP, permettaient déjà de le faire depuis quelques années, mais ces appareils étaient plutôt dispendieux et exigeaient des connaissances plutôt poussées en électronique et en informatique.
Cette fusion entre l’informatique et la radio est connue comme la “Software Defined Radio”, ou la radio définie par logiciel. En d’autres mots, des codes informatiques font le travail qui était auparavant effectué par des circuits spécialisés. Il devient donc possible de décoder des contenus seulement accessibles à certains spécialistes ou à l’aide équipement très dispendieux. Ces contenus incluent les informations émises par les avions, comme le ADS-B. Autrement dit, il devient possible de recevoir la localisation des avions de lignes en temps réel .
Continue reading “Traquer les avions en temps réel avec une antenne et 20$”