A large number of Wikipedia articles are geocoded. This means that when an article pertains to a location, its latitude and longitude are linked to the article. As you can imagine, this can be useful to generate insightful and eye-catching infographics. A while ago, a team at Oxford built this magnificent tool to illustrate the language boundaries in Wikipedia articles. This led me to wonder if it would be possible to extract the different topics in Wikipedia.
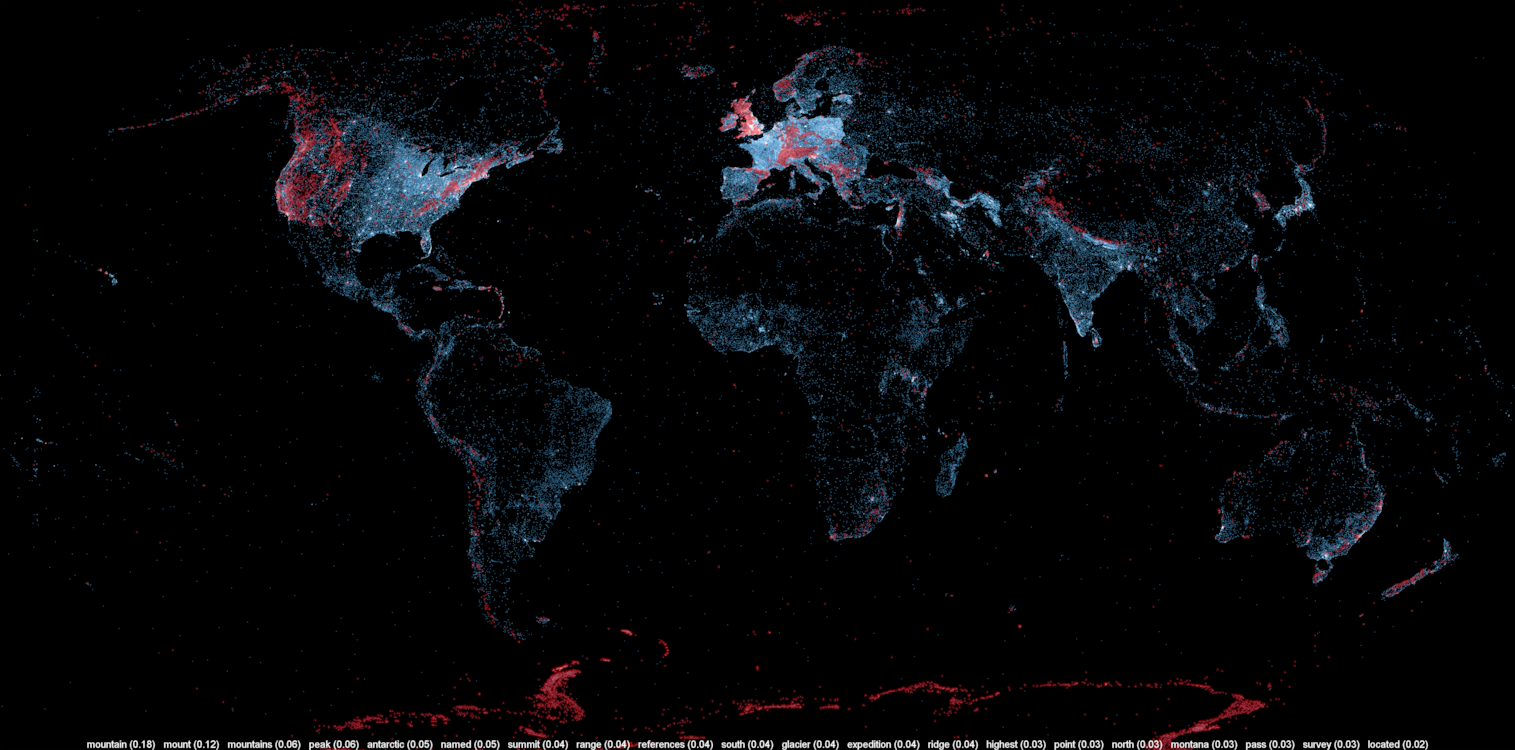
This is exactly what I managed to do in the past few days. I downloaded all of Wikipedia, extracted 300 different topics using a powerful clustering algorithm, projected all the geocoded articles on a map and highlighted the different clusters (or topics) in red. The results were much more interesting than I thought. For example, the map on the left shows all the articles related to mountains, peaks, summits, etc. in red on a blue base map. The highlighted articles from this topic match the main mountain ranges exactly.
Read on for more details, pretty pictures and slideshows.
A bit about the process
You can skip this section if you don’t really care about the nitty-gritty of the production of the maps. Scroll down to get to the slideshows.
Getting the data
The first the step to create these map was to retrieve all Wikipedia articles. There are 1.5 million of them and only a portion (400,000) are geocoded, but this doesn’t matter, because it’s an all or nothing deal: everything must be downloaded. I had to download the raw data from this page. It’s quite a large download at 9GB compressed and it expands to about 40GB once it is uncompressed. I then parsed this very large file to extract the article content, links and geographical coordinates.
Identifying topics
To extract topics from this huge corpus, I used Latent Dirichlet Allocation. This algorithm can extract a given number of topics from a large corpus. Usually the optimal number of topics can be inferred from the likelihood values over several topic runs. However, in this case, since the corpus is very large and each run is very time consuming (50 hours on the most powerful AWS cluster instance), I chose a number relying on an educated guess and my LDA experience.
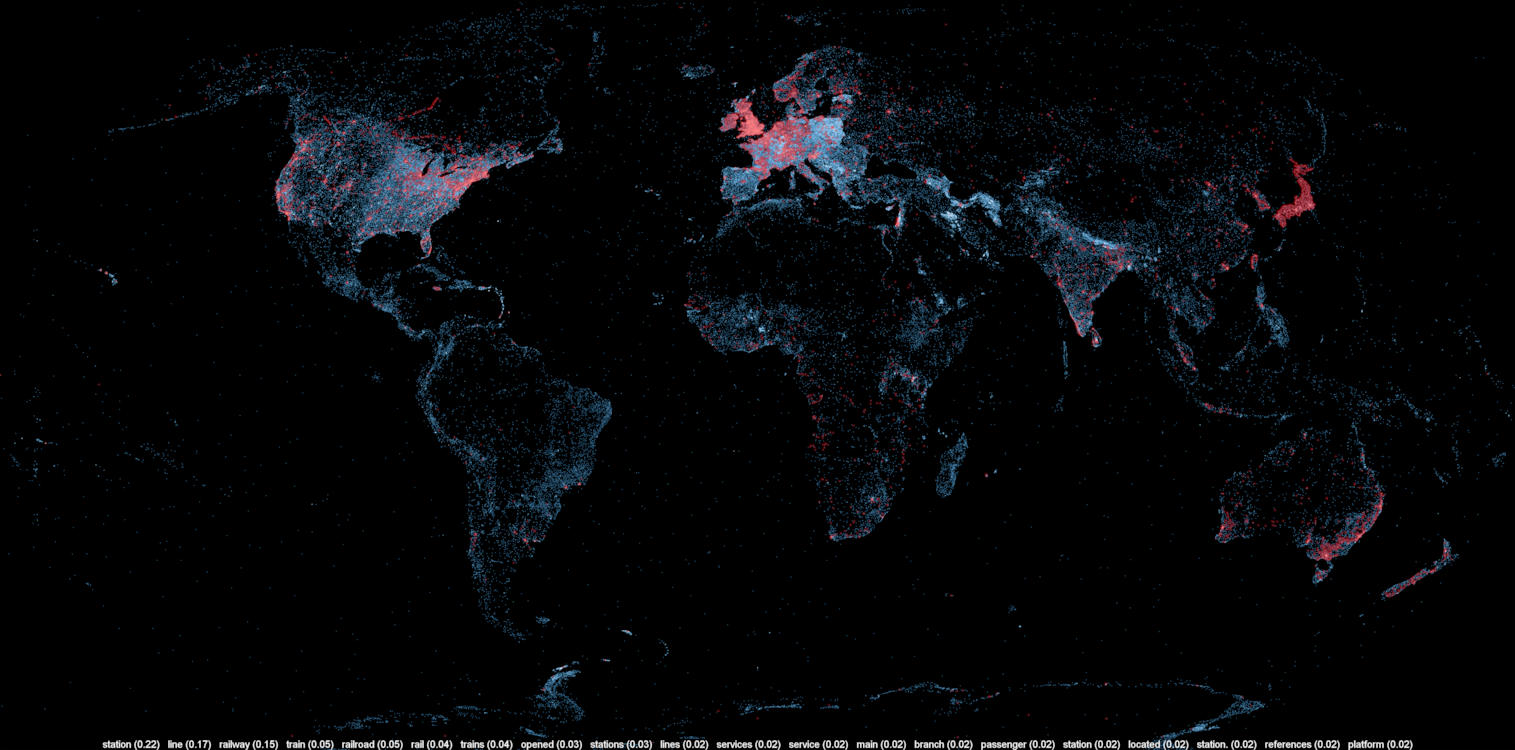
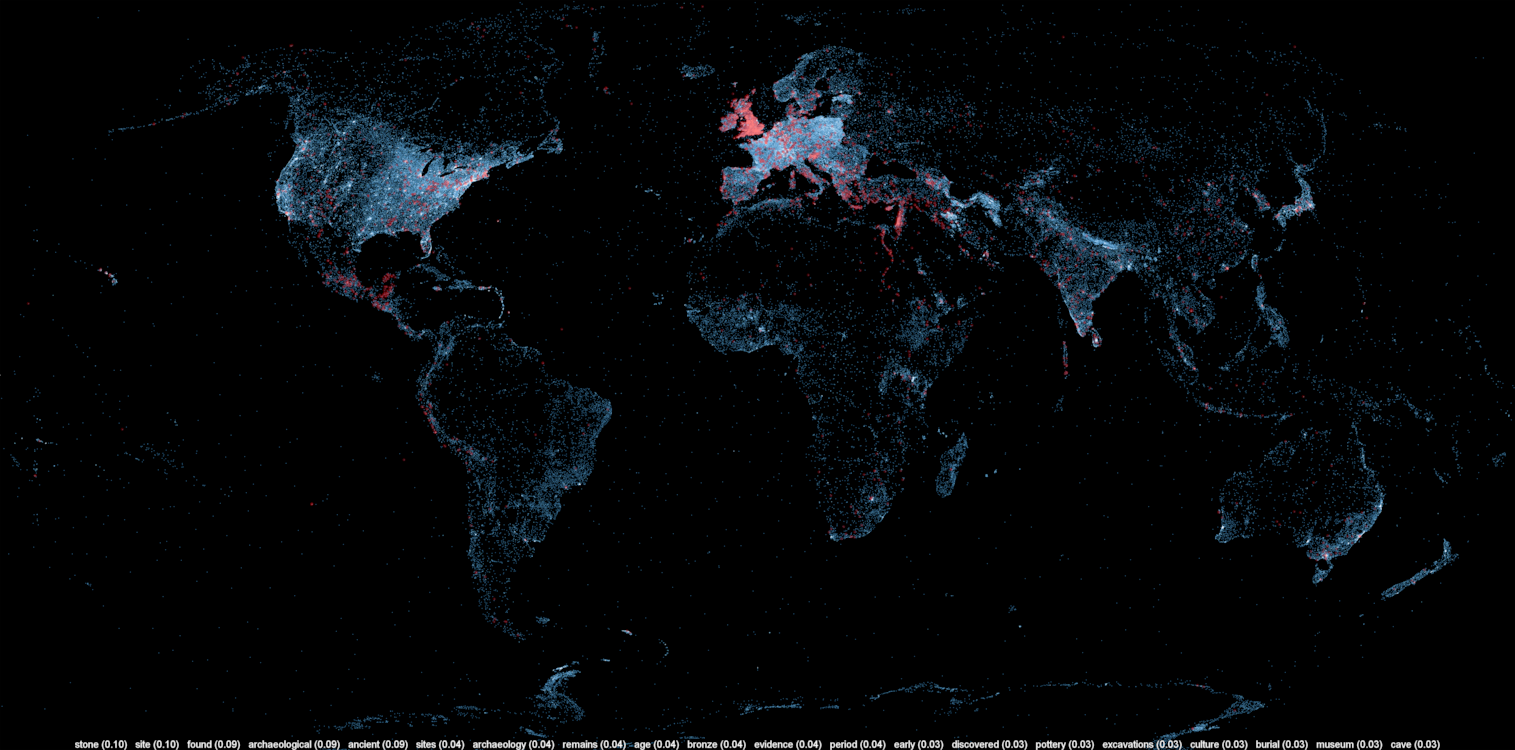
I ran the LDA algorithm using Yahoo’s LDA implementation since it’s quite fast and can be parallelized. After 50 hours, I got 300 different topics linked to 1.5 million articles, but because only 400,000 of them are geocoded, the rest of this post only pertains to these 400,000. You can download the topic descriptions here. The topics are very varied and range from geographical regions, ethnic groups, science, sports (including both kinds of football!), historical sites and even archeological dig sites.
Drawing the maps
The maps were generated from an array of tools ranging from standard Unix utilities to custom developed tools in Python and Java. The previous steps provided me with two datasets, the first one was the geographical coordinates of all Wikipedia articles and the second was a linking table between the topics and the articles.
From there, using a custom tool, I mapped all the points using the Robinson projection. A map with all the articles was rendered in shades of blue and would serve as a base map.
Next, I generated 300 different datasets and rendered the same number of maps where the articles were in red; these were the topic maps. I then overlaid all these maps onto the base map using ImageMagick and added a caption at the bottom of each map to identify each topic.
You can download all the maps in high-resolution (18M pixels – 3MB per map – 900MB total) here.
Interesting Topics
This slideshow illustrates the interesting topics that I found while checking the finalized maps. Most of these maps are not related to political boundaries, but to subjects that are geographically interesting.
[huge_it_gallery id=”5″]
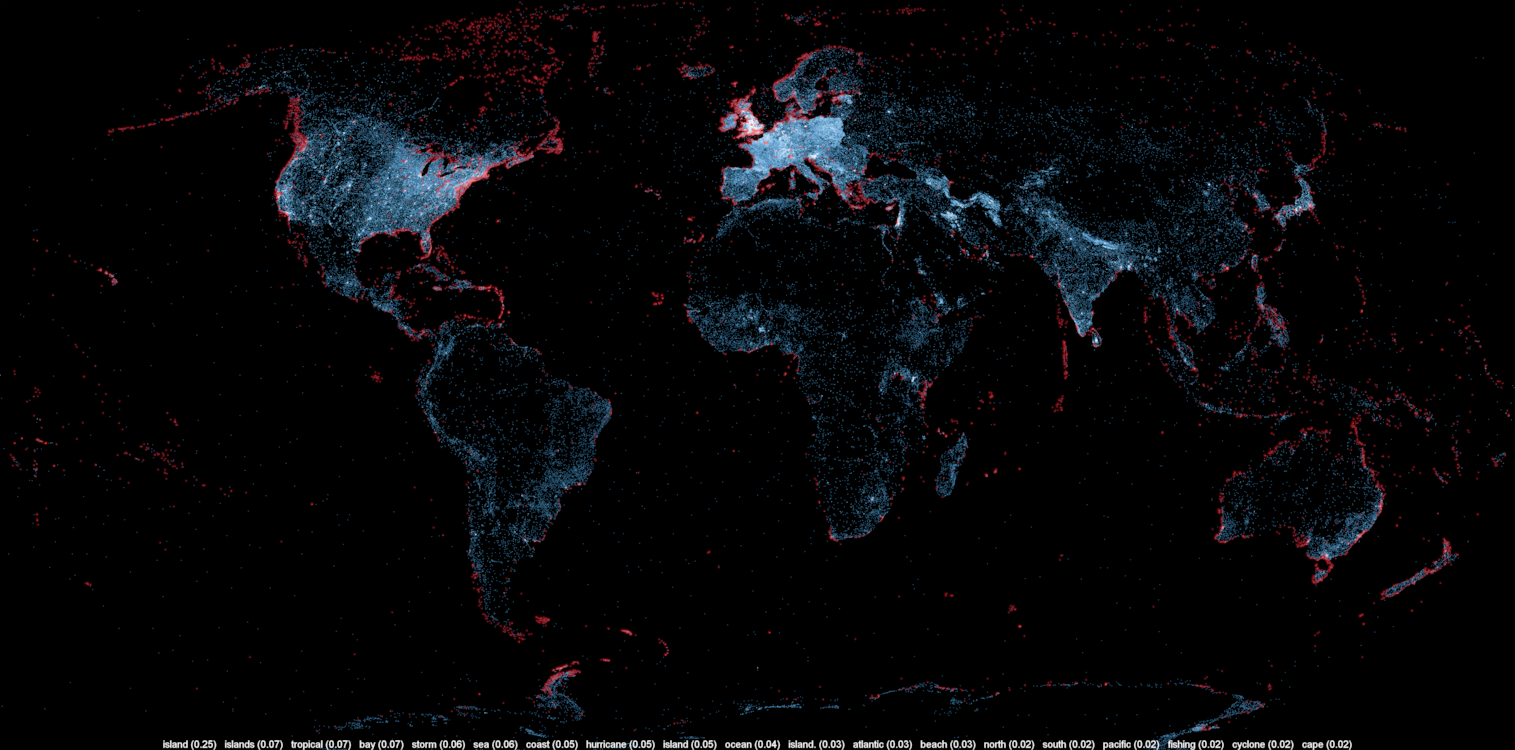
For example, all articles relating to football, climate, music, royal dynasties, naval bases, religions, etc. are highlighted. You can click on the maps to enlarge them and read the captions describing the highlighted articles.
Geographical, Colonial and Ethnic Boundaries
In this slideshow, you can see all the maps with strong geographical topics. Since geography is never far from history, a lot of maps show the colonial past of many countries. As ethnic groups don’t always fall inside political borders, several maps reveal the presence of multiple ethnic or cultural groups within a country or of groups stretching across borders. Other maps show old empires like the Ottoman, Roman or Persian empires.
[huge_it_gallery id=”6″]
Open Data
You can download the geocoded data here. This file includes the topic id, the probability of the article to belong this topic, an internal id, the name of the article, it’s latitude and longitude, and the pagerank of the article.
The raw LDA (including non-geocoded articles) is really massive. If you want it, post a comment (or contact me by email) and I’ll upload it.
I think you should and MUST publish this as a section on wikipedia. Besides this, there might be a business idea here with smaller and more reduced data sets. I am a designer and active in design politics. My natural interest would be to see where other people who are interested in design live to make my network better and streamline my advertising for my products. What do you think?
Hey Olivier! This is absolutely fantastic work; I especially appreciate the amount of effort you went to in programmatically determining the clustering of topics and the resulting maps are really striking as well as informative. If you are willing to share your data, I’d love to play around with it on my own. I’d be happy to share anything interesting that pops up. Any thoughts on the easiest way to share?
Cheers!
Logan
Hi Logan,
I’ve updated the blog post with a link to the raw geocoded data. The data file should be pretty self-explanatory. The column named “prob” is the probability of an article to belong the a certain topic. The Wikipedia page about Latent Dirichlet Allocation will have more details about the clustering algorithm. Also, please note that an article can have many topics. The topics are described in a text file linked in the “Identifying topics” section.
Best,
Olivier
This publication shows outline maps of each county with parishes and clerical districts in Norway. It also contains a list of regions (districts) of Norway and shows which parishes belong to which region. The names of these regions are historical. Their boundaries determined by geological features.